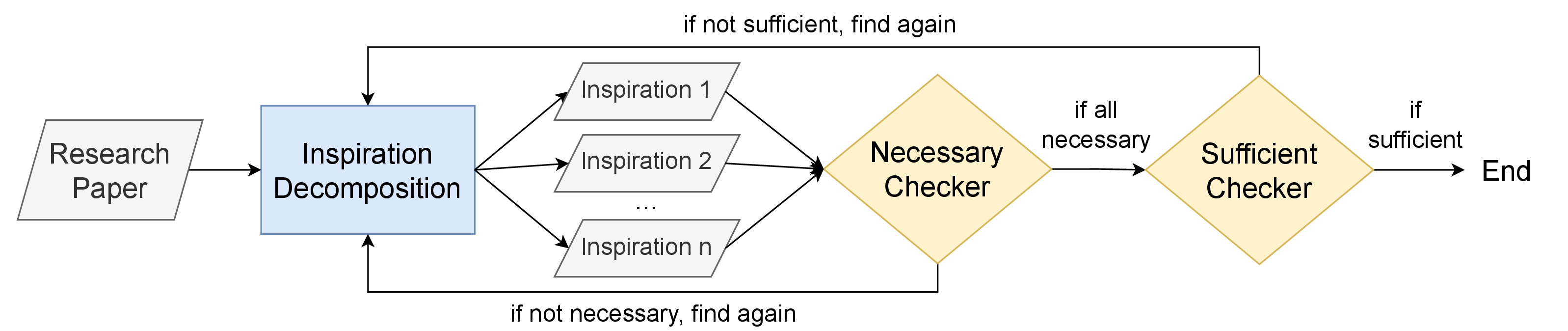
Examples
See the benchmark in action
QuestionHow can a low-cost, eco-friendly adsorbent be developed to efficiently remove methylene blue (MB), a common pollutant, from aqueous solutions?
GPT-4o Selected Inspirations
= ground-truth (correct) = not ground-truth (incorrect)
Biochar-supported zerovalent iron for removal of various contaminants from aqueous solutions
Integrates biochar and zero-valent iron for cost-effective, eco-friendly enhancement of adsorption — directly applicable to MB removal.
Uniform silver nanowires synthesis by reducing AgNO3 with ethylene glycol
Control of particle characteristics informs structural optimization of porous, functionalized adsorbent surfaces.
Biochar composites from biomass & waste residues
Explores metal-enriched biochar composites; relevant but not a ground-truth inspiration for this task.
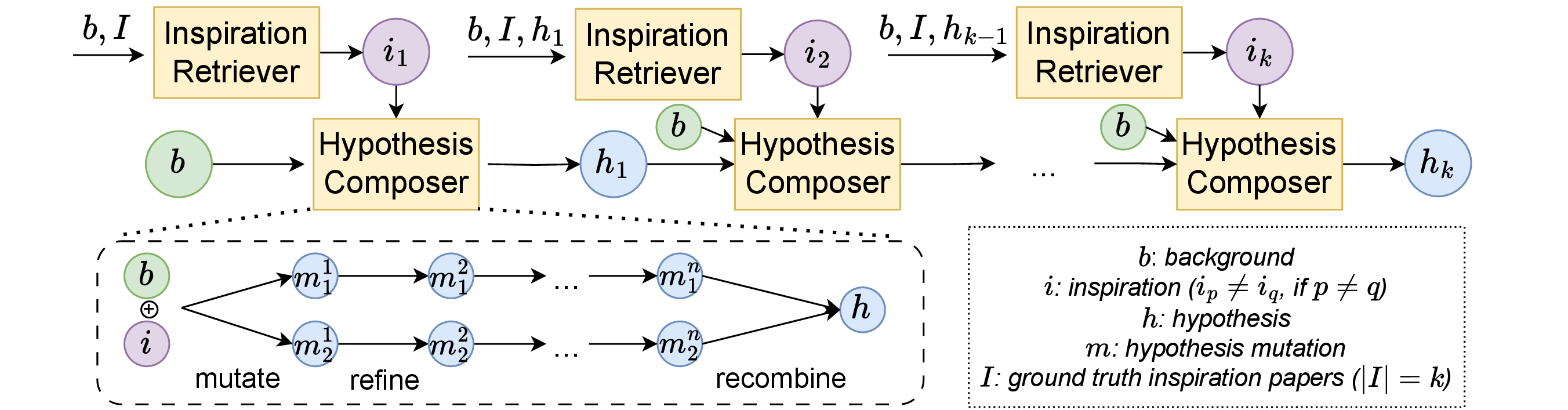
QuestionHow can we enhance the targeted delivery and therapeutic efficacy of dacarbazine in breast cancer cells while minimizing systemic toxicity?
GPT-4o Generated
A hybrid delivery system of sugar-originated carbon nanodots conjugated with dacarbazine, encapsulated in a glucose-mimetic, pH-responsive hydrogel — targeting GLUT1-overexpressing cells via the acidic tumor microenvironment.
Ground Truth
Dacarbazine-primed carbon quantum dots coated with breast cancer cell-derived exosomes (Ex-DC@CQDs) for enhanced targeted delivery, improved tumor-site accumulation, and reduced systemic toxicity.
Score: 2 / 5 Captures carbon nanodot + dacarbazine, but replaces exosome-mediated targeting with a hydrogel mechanism.
QuestionHow does the relationship between SMBHs and their host galaxies evolve during the star-formation peak at redshifts 1–3?
Ground-Truth Hypothesis
During the peak epoch (z ≈ 2), some host galaxies grow faster than their SMBHs — evidenced by an undermassive SMBH accreting at a super-Eddington rate in a high-redshift quasar.
Negative Hypothesis
At redshifts 1–3, coevolution is driven by companion-galaxy interactions and cold-gas inflows shaping molecular-gas accretion under AGN feedback, quantified via ALMA data. GPT-4o picked this